
Partitioning plays a vital role in scaling a database beyond a certain scale of reads and writes. In this essay, we take a detailed look into Partitioning basics and understand how it can help us scale our Reads and Writes beyond a single machine.
What is Partitioning?
A database is partitioned when we split it, logically or physically, into mutually exclusive segments. Each partition of the database is a subset that can operate as a smaller independent database on its own. A database is always deterministically partitioned on a particular attribute like User ID, Time, Location, etc., allowing all records having the same attribute value to reside in the same partition. This will enable us to fire localized queries on a partitioned attribute.

Say a database has grown to be 100GB big, and we choose to partition it on User ID into 4 partitions. To decide which record goes in which partition, we can use a Hash Function applied on the User ID to map one record to exactly one partition. Hence to trace where a record of a particular user resides, we pass it through the same Hash Function and find the owning partition.
We will talk about partitioning strategies in detail in future essays, so keep an eye.
Why do we partition?
We need to partition a database for several reasons, but load distribution and availability are the primary reasons. Let’s dive deeper into each and see how partitioning benefits us.
Load Distribution
A database is partitioned when it needs to handle more reads or writes than one over-scaled database. Our go-to strategy to handle more reads or more writes is to scale the database vertically. Given that vertical scaling has a limit due to hardware constraints, we have to go horizontal and distribute the load across multiple nodes.
Scaling Reads
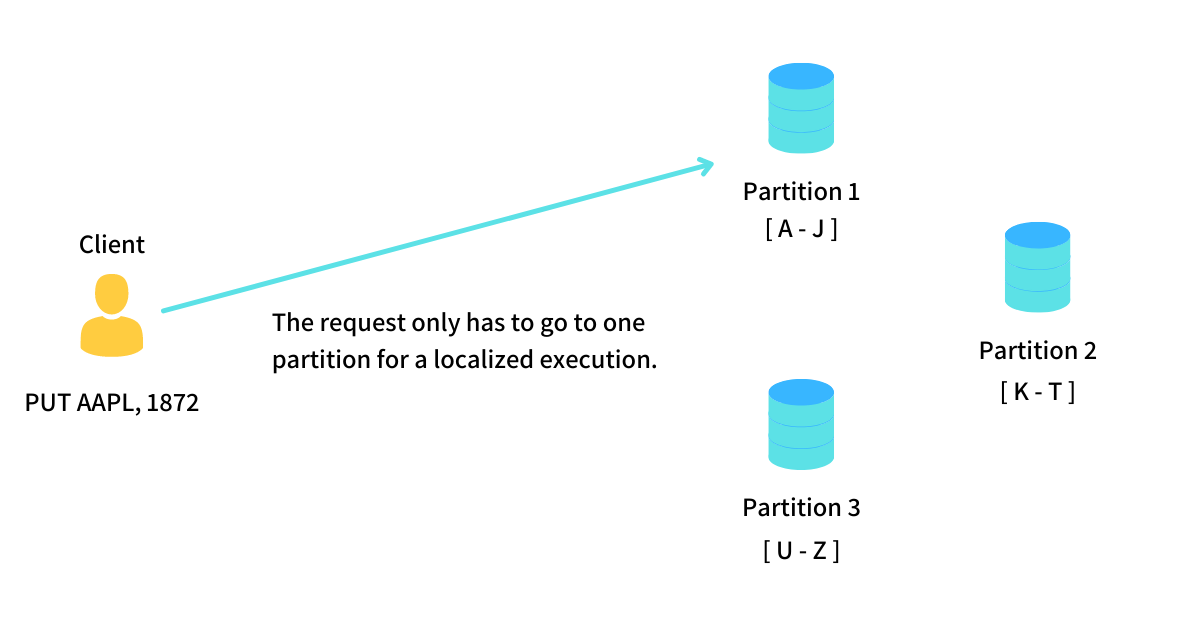
By partitioning a database into multiple segments, we get a significant boost in the performance of localized queries. Say we have a database with 100M rows split into 4 partitions with roughly 25M rows each. Now, instead of one database supporting querying over 100M rows, we split the read load across 4 databases allowing us to quickly execute the query and serve the results to the users.
If the read query is localized by partitioned attribute, we need only one (of the four) partitions to execute the query and get the results, thus distributing the read load. For example, in a blogging platform, if our database is partitioned by User ID and we want to find the total number of posts made by a user, this query only needs to be executed on one small partition of data.

Suppose the read queries require us to fetch records from multiple partitions, given that each partition is independent. In that case, we can parallelize the execution and then merge the results before sending them out to the users. In either case, we get a massive performance boost in query execution.

Scaling Writes
In a traditional Master-Replica setup, there is one Master node that takes in all the write requests, and to scale reads, this Master has a few configured Replicas. To handle more Write operations in such a setup, one approach is to scale the Master node vertically by adding more CPU and RAM. The second approach is to scale it horizontally by adding multiple nodes acting as independent Multiple Master nodes.
Given that vertical scaling has a limit, scaling writes that adding multiple independent Master nodes becomes a go-to strategy beyond a certain scale, where Partitioning plays a key role. In a partitioned setup, since one record can is present on one partition, the total write operations are evenly distributed across all the Master nodes, allowing us to scale beyond a single machine.
Improving Availability
By partitioning a database, we also get a massive improvement in data availability. Since our data is divided across multiple data nodes, even if one of the nodes abruptly crashes and becomes unrecoverable, we only lose a fraction of our data and not the whole of it.
We can further improve the availability of our data by replicating it across multiple secondary data nodes. Thus each partition resides on multiple data nodes, and in case of them crashes, we can fully recover the lost data from the secondary node, giving our fault tolerance a massive boost.

Each record thus belongs to exactly one partition, but the replicated copy of the record can be stored on other data nodes for fault tolerance. These replicated copies are similar to Read Replicas that either synchronously or asynchronously follow the primary copy and keep itself updated.
Types of partitioning
Data can be partitioned in two ways - Horizontal and Vertical. In terms of relational databases, Horizontal Partitioning involves putting different rows into different partitions, and Vertical Partitioning involves putting different columns into separate partitions.
Horizontal partitioning is a very common practice in scaling relational and non-relational databases. It allows us to visit just one partition and get our query answered. It also enables us to split our query load across partitions by making one partition responsible for a particular row/record.
Vertical partitioning is seen in action in Data Warehouses, where we have to crunch a lot of numbers and fire complex aggregation queries. Vertical partitioning is particularly useful when we are not querying all the columns of a particular record and refer to querying a fewer set of columns in each query.