Arpit's Newsletter read by 100,000 engineers
Weekly essays on real-world system design, distributed systems, or a deep dive into some super-clever algorithm.
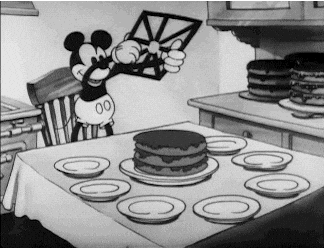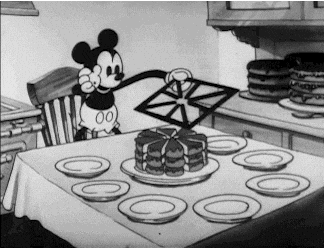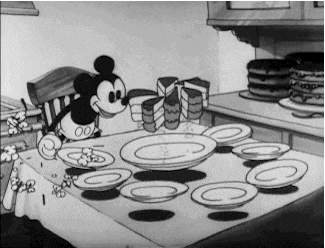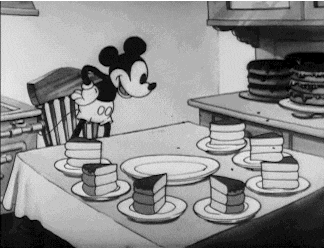
Sharding and partitioning come in very handy when we want to scale our systems. Let’s talk about these concepts in detail.
A database server is just a database process (like MySQL, MongoDB) running on a virtual server like EC2. Now when we put our database in production it starts getting from real good traction, say 100 writes per second (WPS).
Say, your product started getting some traction, and we find that the database is not able to handle the load, we scale it up by adding more CPU, RAM, and Disk to the server. This way we are now handling 200 WPS.
If we see nor reads then can also choose to add a Read Replica and divert some of the read traffic to this node, while the master node can take in 200 WPS.
Say, your product went viral and you now got 5x more load which means now you have to handle 1000 WPS. To achieve this you again scale it up vertically and handle the desired load.
Say, you now cracked the PMF and are getting some really solid traction and need to handle 1500 WPS, and when you visit the database console you found out that it is not possible to vertically scale your database any further, so how do you handle 1500 WPS?
This is where the horizontal scaling comes into the picture.
We know one database server can handle 1000 WPS, but we need to handle 1500 WPS, so we split the data into half and split it across two databases such that each database owns half of the data and all the writes for that data goes to that particular instance.
This way each server will get 750 WPS, which it can very easily handle, and owns 50% of the data. Thus by adding more database servers we handled 1500 WPS (more than what a single machine could handle)
Each database server in the above architecture is called a Shard while the data is said to be partitioned. Overall, a database is sharded and the data is partitioned.
It is possible to have more partitions and fewer shards and in that case, each shard will own multiple partitions. Say, we have 100GB of data and it is split into 5 partitions and we have 2 shards. One shard will be responsible for 3 partitions while the other for 2.
Here's the video ⤵
Alongside my daily work, I also teach some highly practical courses, with a no-fluff no-nonsense approach, that are designed to spark engineering curiosity and help you ace your career.
A no-fluff masterclass that helps SDE-2, SDE-3, and above form the right intuition to design and implement highly scalable, fault-tolerant, extensible, and available systems.
An in-depth and self-paced course for absolute beginners to become great at designing and implementing scalable, available, and extensible systems.
A self-paced and hands-on course covering Redis internals - data structures, algorithms, and some core features by re-implementing them in Go.
Arpit's Newsletter read by 100,000 engineers
Weekly essays on real-world system design, distributed systems, or a deep dive into some super-clever algorithm.